What have I learned from the implementation of deep learning paper?
This article may be useful if you work on implementing deep learning/ computer vision algorithms.
*Edit: code is public https://github.com/eric-yyjau/pytorch-superpoint/.
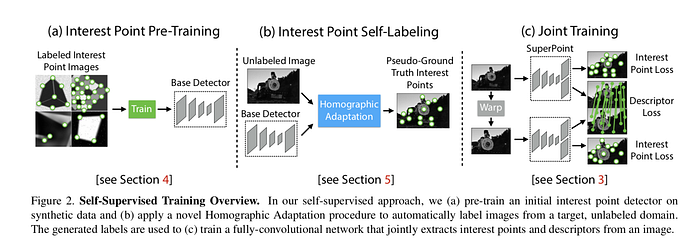
Due to the need of my research project “deep SLAM,” I work on implementing the paper, SuperPoint from Daniel. et al. in MagicLeap. The resources I have include the inference model in pytorch from the author, and the 3rd-party implementation in tensorflow. The goal is to train our model in pytorch that achieves comparable performance.
It turns out that I was stuck by the reimplementation for over 3 months (Jan. to April). I would like to share my experience on the tricks and methodology, mainly inspired by my partner Rui Zhu.
The most important things in the programs are model, data, and loss functions
Therefore, when things are not working well, the questions we need to ask are:
What is your model? What is your data? What is your loss?
In my case, I made mistakes in all the things. Let me briefly dive in the tricks I fell into.
- What is your model?
I use the inference model from the original author as my training model. However, I didn’t carefully compare the structure of this model with the model in tensorflow. Since we have all the codes in 3rd-party version, we should first follow all the details in that. I missed the batch normalization layer, which made a huge difference.
- What is your data?
Data is super important, especially the augmentation in this project. The data feeds in the model decides how well the model can learn. In this project, we have photometric augmentation (noise or brightness), and homography augmentation (warp the images). I rewrote the functions or utilized package. The key is to realize exactly the same data augmentation. Since the augmentation consists of random sampling, it gets hard to compare my function with 3rd-party version.


- What is your loss?
The loss functions define the goal of the training. However, the wrong loss function may still trainable but generates worse performance.
It’s hard to know the reason when something goes wrong. It could be model, data or loss functions. Therefore, we need the other tools to help us, which will be briefly discussed below.
The engineering skills I developed
- Visualize everything
We check the modules by visualizing it. We visualize the input, the prediction, the masks, intermediate results in training, and testing results. At this time, jupyter notebook is a good tool. You can easily edit the functions in python script and test the small module.
However, visually correctness doesn’t mean that it is bug free. We check the data one by one and detailedly. Then, we can apply metrics to verify the correctness.

- Unit test everything
My code base includes around 10 config files, and 4 datasets in the 3 stage training. I failed to modularize and test my codes strictly, which made me pay the debts afterwards.
For example, I didn’t unit test the data loader itself, but debug from the training script. The design makes the process more complex and slower as we need to run the training script every time.
For my training function, I didn’t wrap it in a ‘class.’ It becomes much clear after I wrap the 500-line code into a 500-line class with 20 functions and its own testing code. I don’t need to pass the config multiple times to function. The model loader and saver can also be utilized repeatedly.
- Metrics speak
Not only the metrics for testing, but also the metrics during training are important. I compare the precision-recall during training with 3rd-party version, which highly relates to the performance of our training.
When you feel like to skip the detail, please be super careful.
The key is to take care of every single detail and keep things manageable. Write the comments, keep the log files, and manage codes in github. So that, when my partner asks if I’m sure about this part, I can say ‘yes’ as I test it carefully.
Ref
- paper: Superpoint: Self-supervised interest point detection and description
- rpautrat/SuperPoint: Efficient neural feature detector and descriptor
- MagicLeapResearch/SuperPointPretrainedNetwork: PyTorch pre-trained model for real-time interest point detection, description, and sparse tracking (https://arxiv.org/abs/1712.07629)
- eric-yyjau/pytorch-superpoint: Superpoint Implemented in PyTorch: https://arxiv.org/abs/1712.07629